Home¶
![]()
An ecosystem for producing and sharing metadata
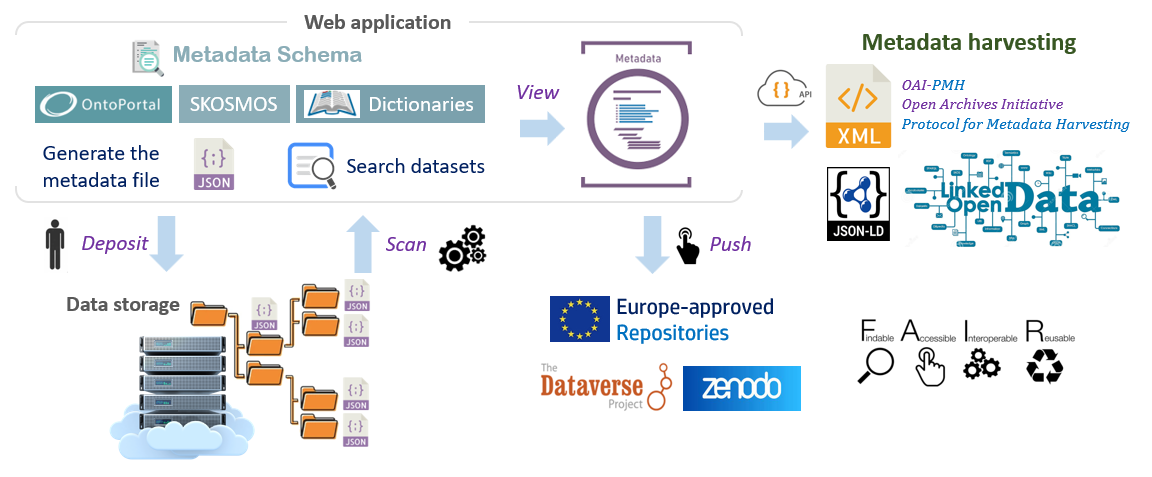
Foster good data management, with data sharing in mind¶
Sharing descriptive Metadata is the first essential step towards Open Scientific Data. With this in mind, Maggot was specifically designed to annotate datasets by creating a metadata file to attach to the storage space. Indeed, it allows users to easily add descriptive metadata to datasets produced within a collective of people (research unit, platform, multi-partner project, etc.). This approach fits perfectly into a data management plan as it addresses the issues of data organization and documentation, data storage and frictionless metadata sharing within this same collective and beyond.
Main features of Maggot¶
The main functionalities of Maggot were established according to a well-defined need (See Background).
- Documente with Metadata your datasets produced within a collective of people, thus making it possible :
- to answer certain questions of the Data Management Plan (DMP) concerning the organization, documentation, storage and sharing of data in the data storage space,
- to meet certain data and metadata requirements, listed for example by the Open Research Europe in accordance with the FAIR principles.
- Search datasets by their metadata
- Indeed, the descriptive metadata thus produced can be associated with the corresponding data directly in the storage space then it is possible to perform a search on the metadata in order to find one or more sets of data. Only descriptive metadata is accessible by default.
- Publish the metadata of datasets along with their data files into an Europe-approved repository
{kind=link}
See a short Presentation and Poster for a quick overview.
Overview of the different stages of metadata management¶
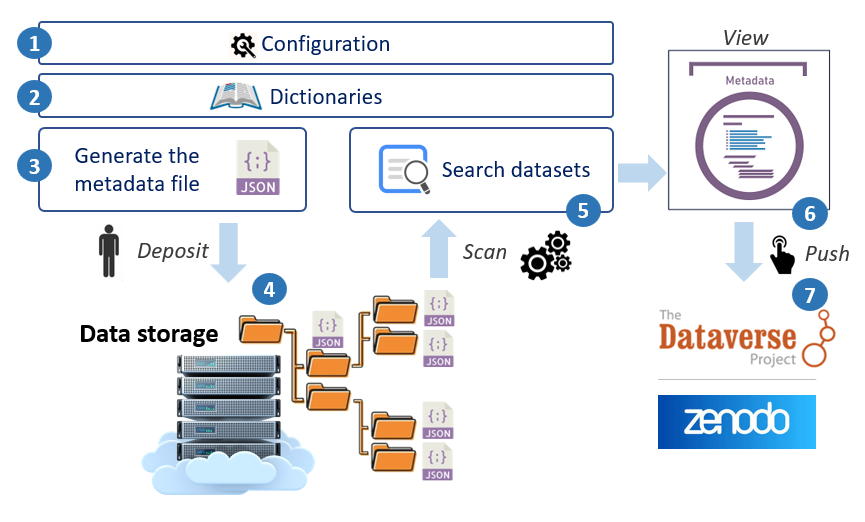
Note: The step numbers indicated in the figure correspond to the different points developed below
1 - First you must define all the metadata that will be used to describe your datasets.
{kind=link}
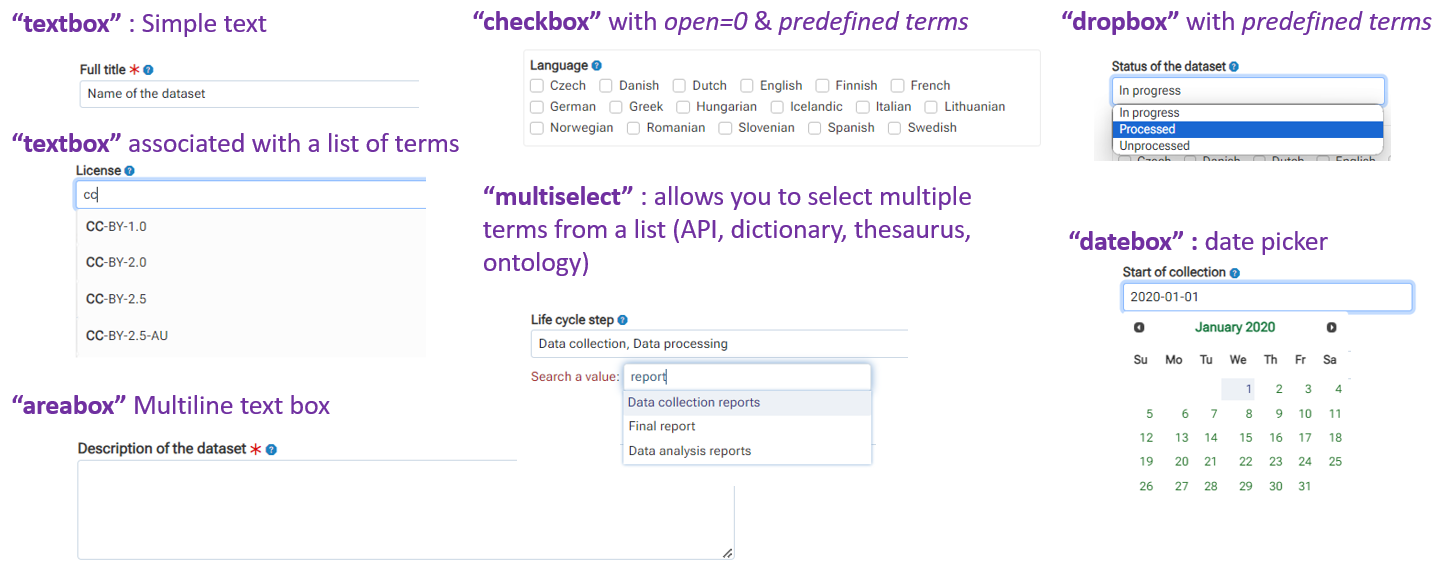
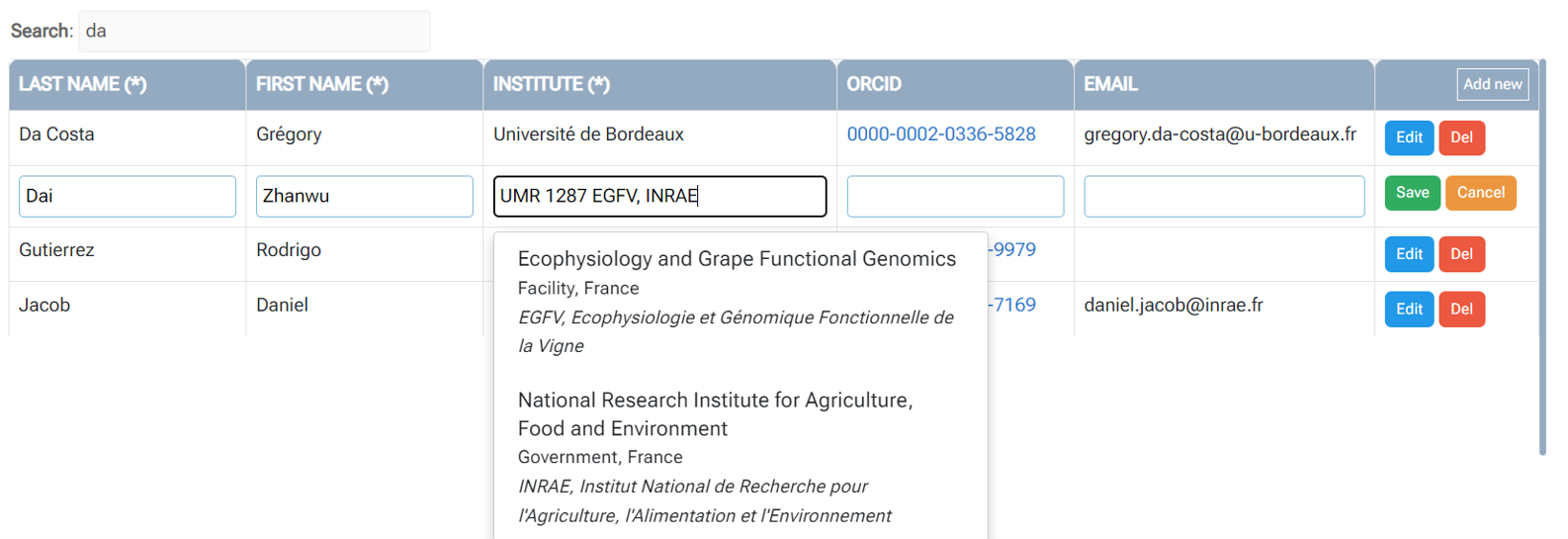
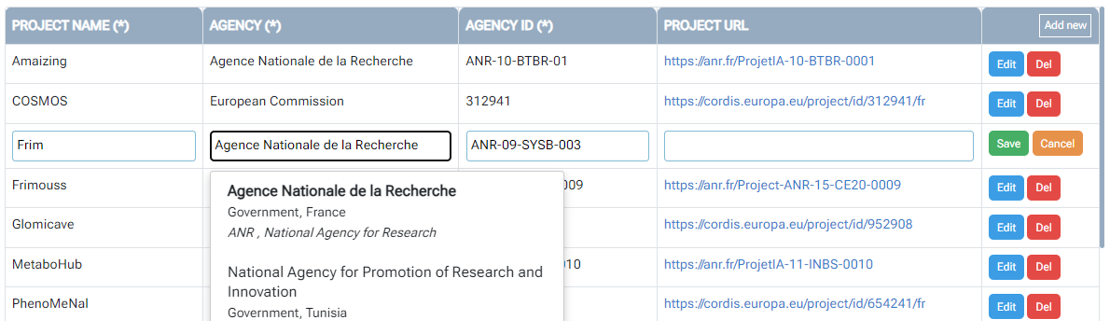
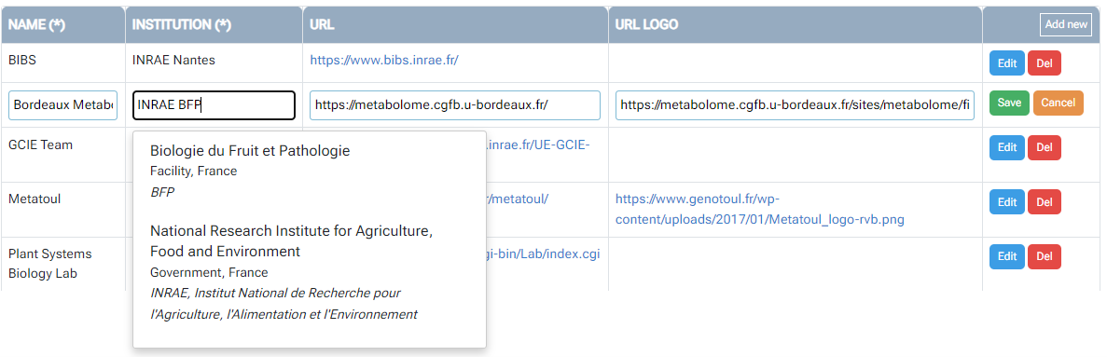
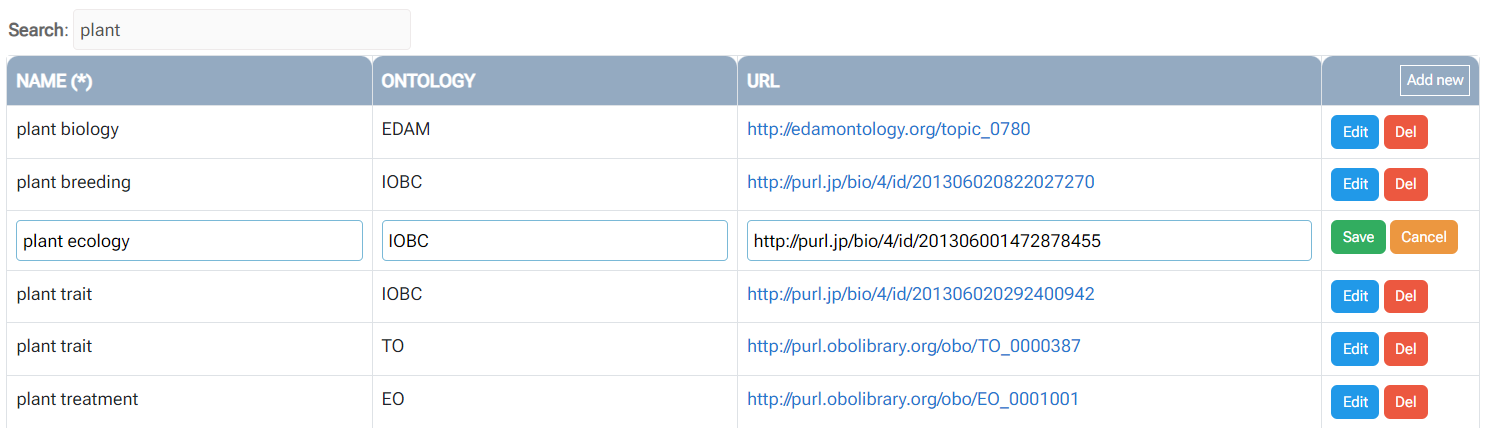
2 - Entering metadata will be greatly facilitated by the use of dictionaries.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
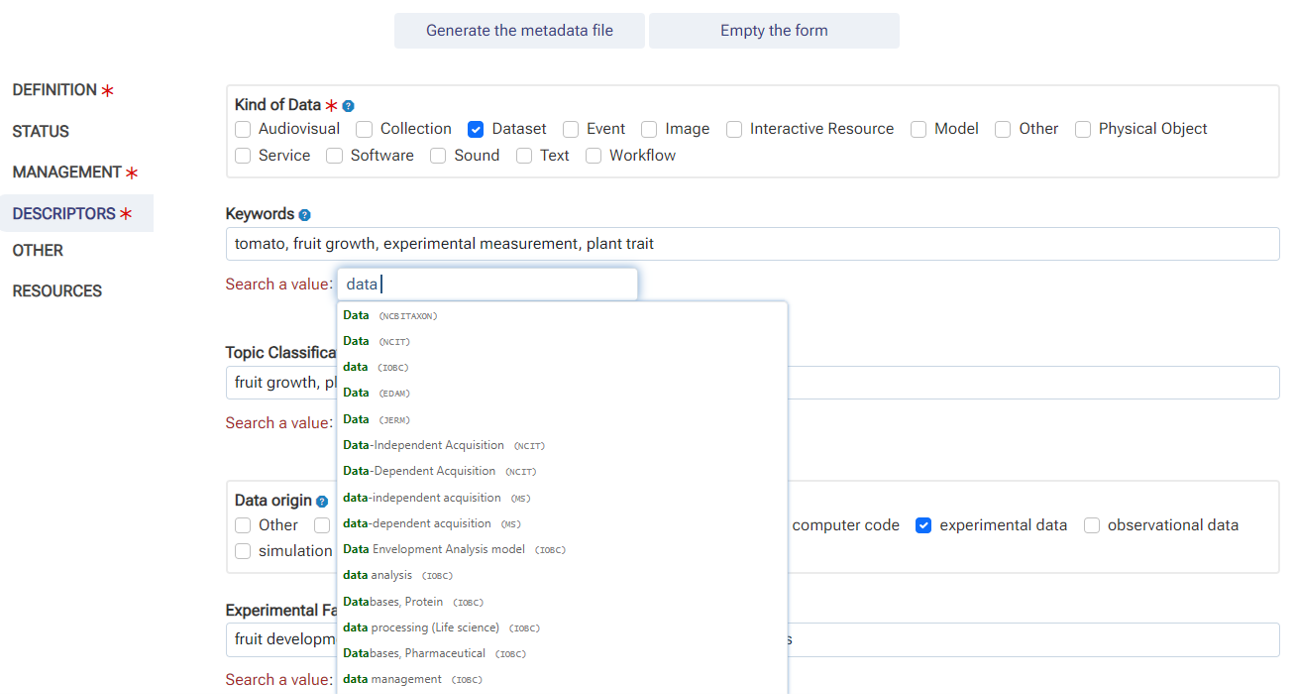
3 - The web interface for entering metadata is entirely built on the basis of definition files.
{kind=link}
4 - The file generated in JSON format must be placed in the storage space reserved for this purpose.
5 - A search of the datasets can thus be carried out on the basis of the metadata.
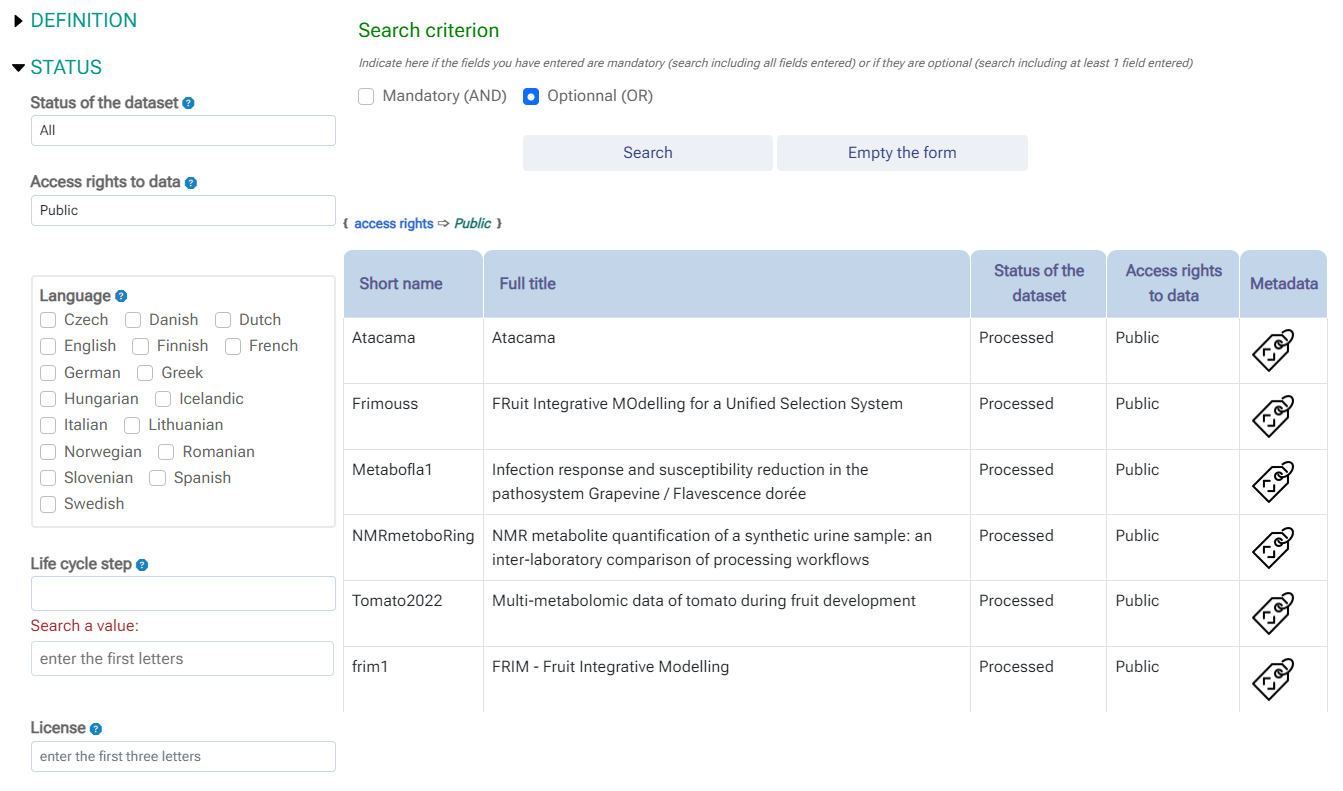{kind=link}
6 - The detailed metadata sheet provides all the metadata divided by section.
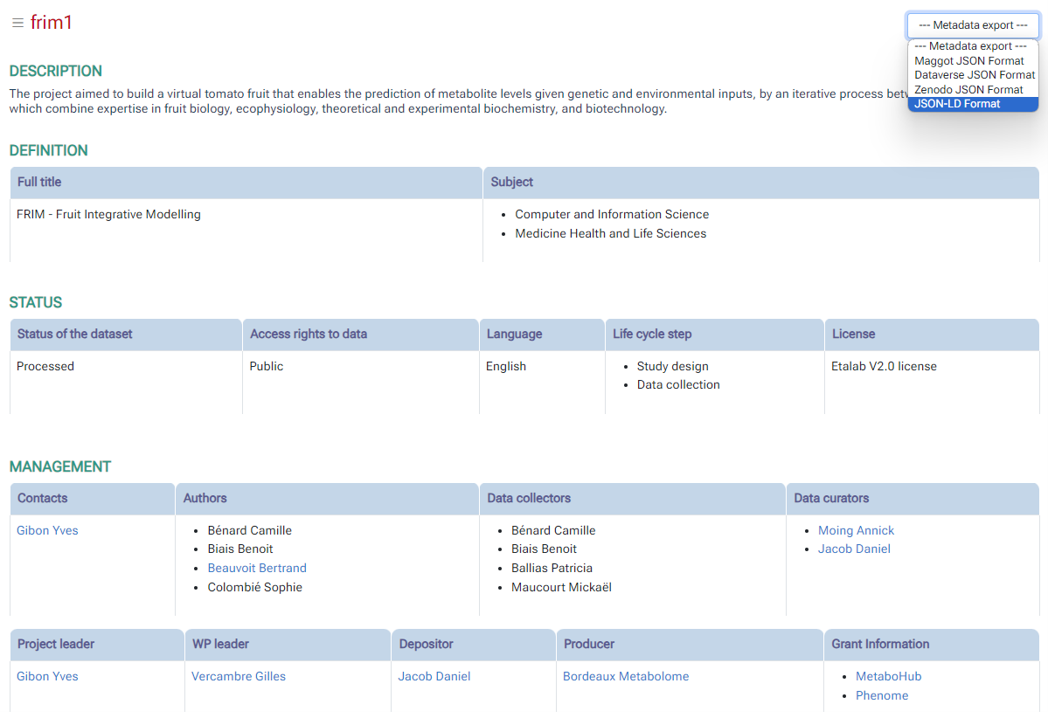{kind=link}
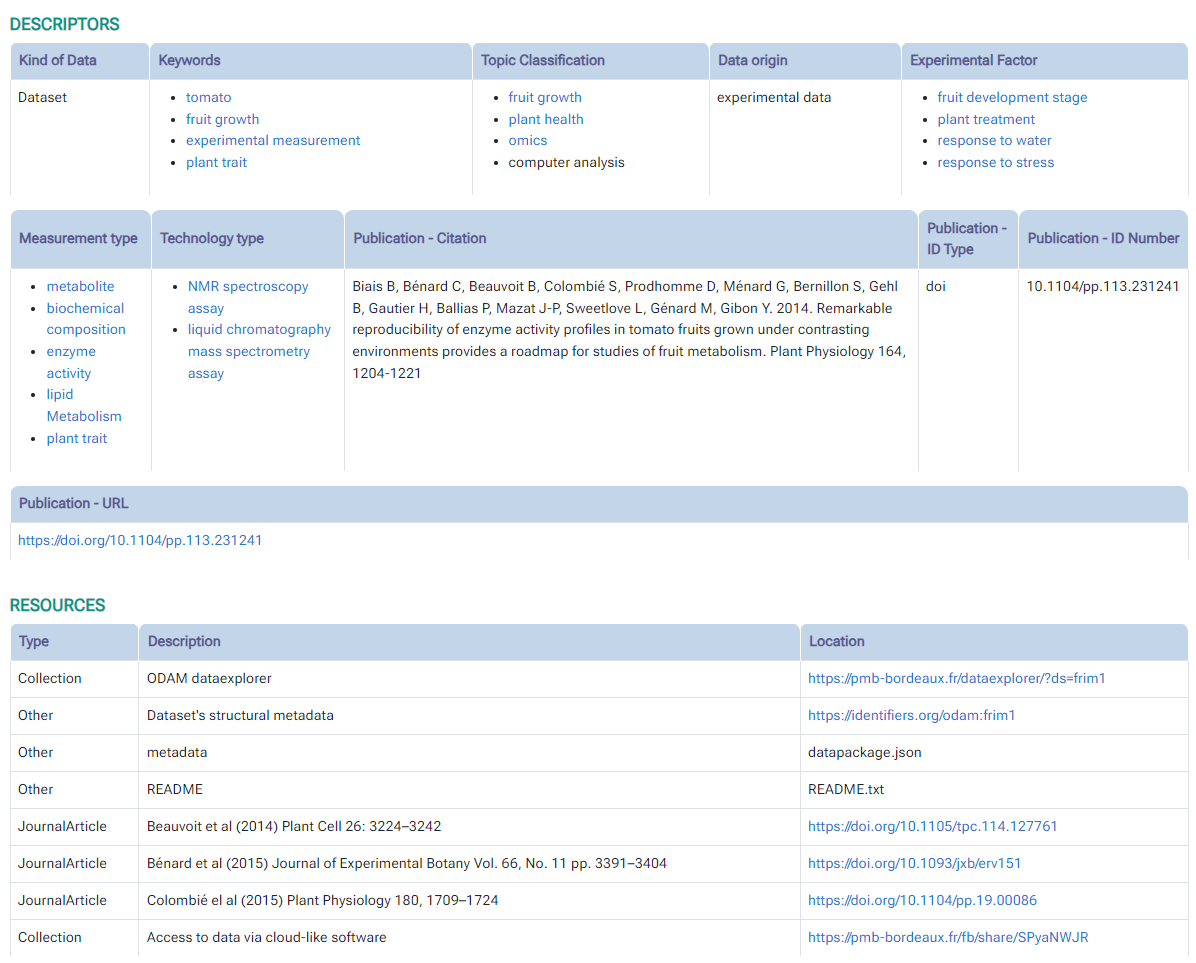{kind=link}
7 - Finally, once you have decided to publish your metadata with your data, you can choose the repository
Additional key points¶
Being able to generate descriptive metadata from the start of a project or study without waiting for all the data to be acquired or processed, nor for the moment when one wish to publish data, thus respecting the research data lifecycle as best as possible. Read more.
The implementation of the tool requires involving all data stakeholders upstream (definition of the metadata schema, vocabularies, targeted data repositories, etc.); everyone has their role: data manager/data steward on one side but also scientists and data producers on the other. Read more.
A progressive rise towards an increasingly controlled and standardized vocabulary is not only possible but even encouraged. First we can start with a simple vocabulary dictionary used locally and grouping together domain vocabularies. Then we can consider the creation of a thesaurus with or without mapping to ontologies. The promotion of ontologies must also be done gradually by selecting those which are truly relevant for the collective. A tool like Maggot makes it easy to implement them (See Vocabulary). Read more.
![]()