Collection of datasets
Collection of Datasets¶
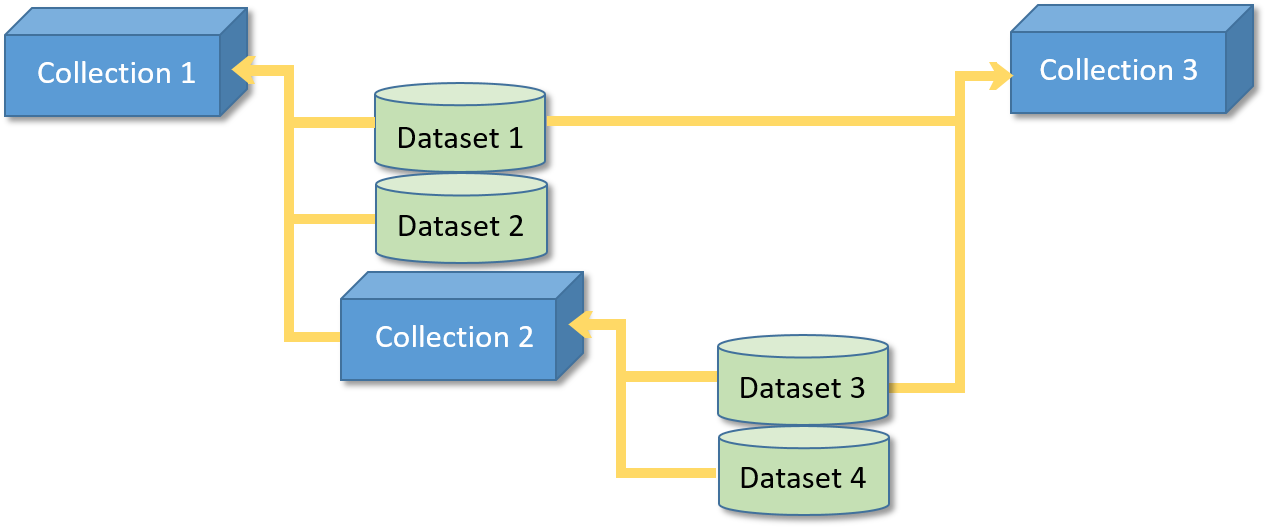
A collection in the sense of ODAM is a set of datasets. The link between datasets can be very varied, either a project, a theme, or anything else. For example, if you have produced several datasets within the same project, it can be interesting to manage them by creating a link between them. This link is precisely what in ODAM we call a collection.
In ODAM, a collection has exactly the same structure as a dataset, i.e. there are data files (only one in fact) and the two metadata files (s_subsets.tsv & a_attributes.tsv) previously described in the main section (see Data preparation). By keeping the same structure as a dataset, it means that we can use the same API for both a collection and a datatset.
You can see an example of a collection accessible online via the data explorer.
Remarks:
- You can not only manage collections of datasets but also collections of collections and thus manage a hierarchy in your datasets.
- A dataset or collection can be declared as a member of several collections.
Content of the collection¶
only one file is used to describe the content of the collection. Here is its structure :
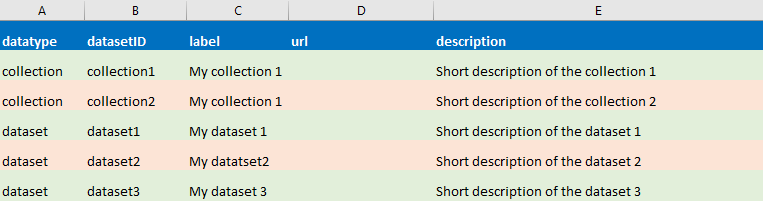
A column : Data type.
- Put simply 'dataset' for a dataset or 'collection' for collection
B column : the dataset identifier
- i.e the name of the dataset/collection directory
C column : a short label more explicite than the dataset identifier
- must be less than 20 characters
D column : API URL of the dataset or the collection
-
by default, left empty this field. This means that the data are on the same server than the collection
-
Otherwise, put the URL of the API.
E column : Description of the dataset or the collection
- the allowed characters are: 0-9 a-z A-Z , : + * () [] {} - % ! | / . ?
Metadata of the collection¶
In addition to the file describing the content of the collection, it is necessary, as with any ODAM dataset, to attach the two metadata files previously described in the main section, namely s_subsets.tsv and a_attributes.tsv (see Data preparation). The difference is that for a collection these two files are already predefined for any collection and very little modification is required.
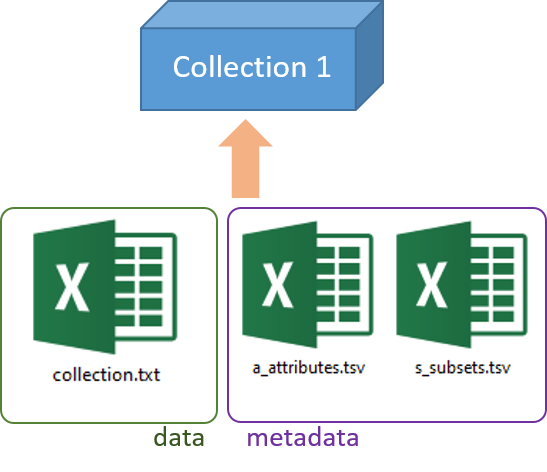
s_subsets.tsv¶
Only the description must be changed according to your collection. This description must be as short as possible (20 characters), because it appears in the data explorer as the title of the collection in the top bar. You can also change the name of the file describing the content of the collection but this is not necessary.

a_attributes.tsv¶
In this file, nothing must be changed. It must be added as is.

Additional information¶
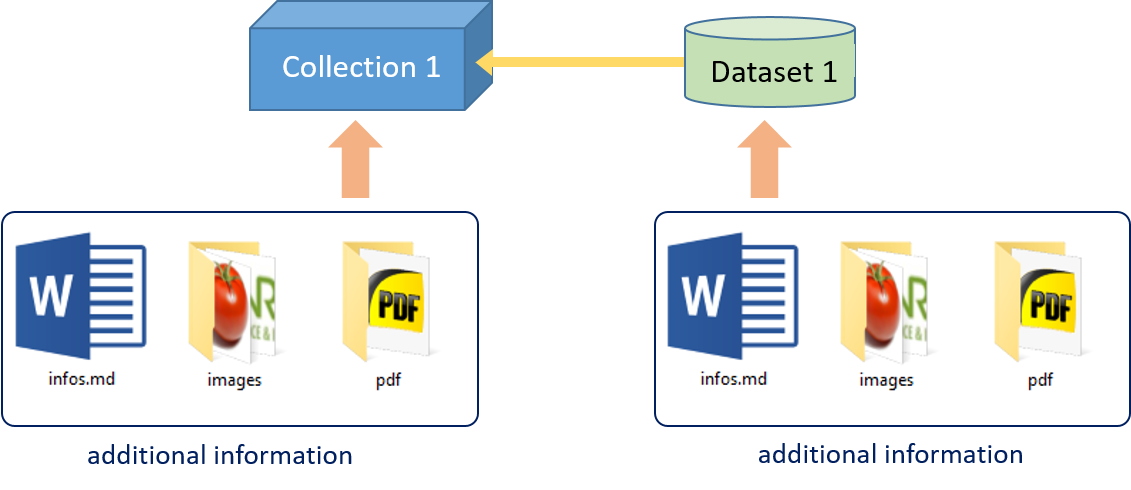
In the same way as with a dataset (reminder: a collection is seen as a dataset in ODAM), it is possible to add an information file (i.e. infos.md), as well as images and PDF files. ( See Data preparation)
Download¶
You can download the files describe in this section as template: